
Deploy Private AI Endpoints in Seconds
Spin up secure, Swiss-hosted LLMs instantly. No logging, no setup, pay only for what you use.




Introducing MotionQ
AI for performance and effortless use


Blazling Fast Inference
Our Swiss-based infrastructure cuts latency and boosts responsiveness. Combined with optimized model serving, your users get consistently fast results.
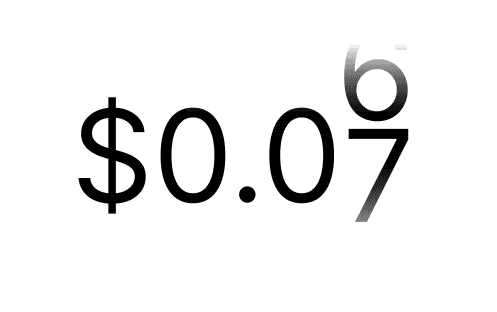
Pay Only What You Use
You’re charged solely for the tokens processed. No subscriptions, no hidden tiers. Predictable costs that scale with your actual workload.
Automatic Scaling, Zero Maintanance
We handle all scaling behind the scenes, from small bursts to heavy traffic spikes. No infrastructure tuning, no capacity planning, no headaches.
Process
Empower your growth with AI-driven solutions
Industries
Privacy where it's needed
Certain industries handle sensitive data that demands strict privacy, including finance, healthcare, and legal services. MotionQ's Private AI ensures these sectors can leverage powerful LLMs without risking compliance, data leaks, or exposure of confidential information.
Finance
E-commerce
Healthcare
SaaS
Real Estate
Logistics
Legal
Education

Compare
Why Choose MotionQ
MotionQ gives fast, private, and fully managed LLM endpoints that scale with your product.
Other Providers
MotionQ
FAQ